Member-only story
Apache Spark : A comparative overview of UDF, pandas-UDF and arrow-optimized UDF

What does UDF mean and why do they exist ?
UDF stands for User Defined Function. Those functions can be written in Python, R, Java and Scala, enabling more personalized and complex data manipulation.
Indeed, they are designed to make Spark framework more accessible and flexible for a wider range of users. This encourages broader adoption by providing the flexibility needed for various data processing tasks.
1. Standard UDF
UDFs in Apache Spark can be written using various programming languages such as Python, Scala, Java, and R. Each language offers a distinct implementation approach with differences in performance and functionality.
When executed, UDFs are crafted from the driver node to the executors nodes and this regardless the programming language used.
1.1 Java and Scala UDF
UDFs ran within the Java Virtual Machine (JVM) with minor performance penalties. In fact, they do not capitalize on Spark’s advanced optimization features such as Whole-Stage Code Generation and Just-In-Time (JIT) compilation, which are designed to enhance performance.
1.2 Python UDF
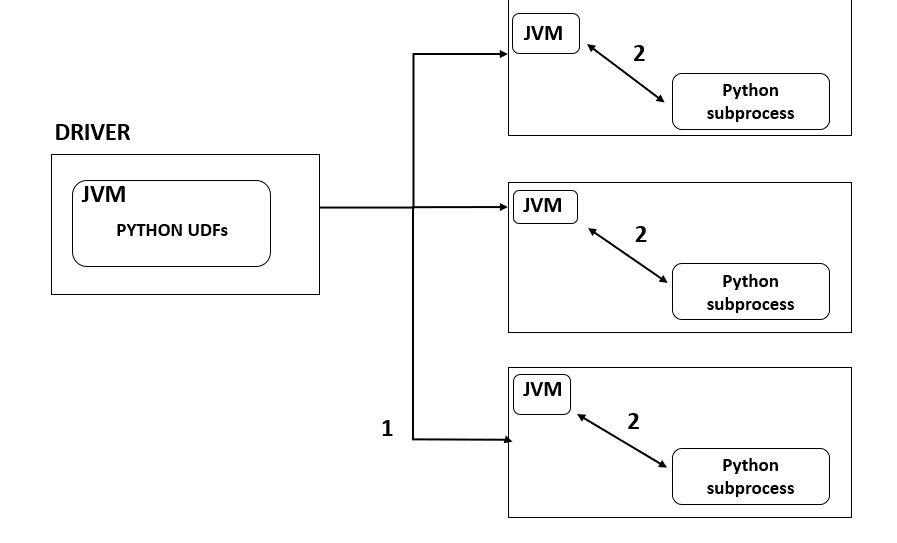
1- Python UDF function is sent to each executors [1]
2- Unlike Java and Scala UDF, the function is not executed within the JVM. Actually, a python worker process is opened on each executor and data is serialized using pickle and send to the python function. The response of the UDF is then deserialized back to the JVM. [1]
1.3 Notes and considerations on classic UDFs
- Starting a python process on each executor is expensive given data serialization and deserialization.
- Once the data serialized to the python UDF , spark does not manage the memory which can lead to serious OOM (Out Of Memory) issues.
- If the column used as input for UDF contains Null, you…
